threshold
The turn is real to the engine but not to a person: a few degrees of bend announced as a maneuver. Fixable by tuning turn-classification parameters. We found almost none of these.
ARI needs turn-by-turn guidance, and the instructions our engine produces today are far too
chatty. This page summarizes the guidance-comparison spike: what we measured on the production
graph, what is actually causing the noise, and what we should do about it. Source material lives
in reference/guidance-comparison.
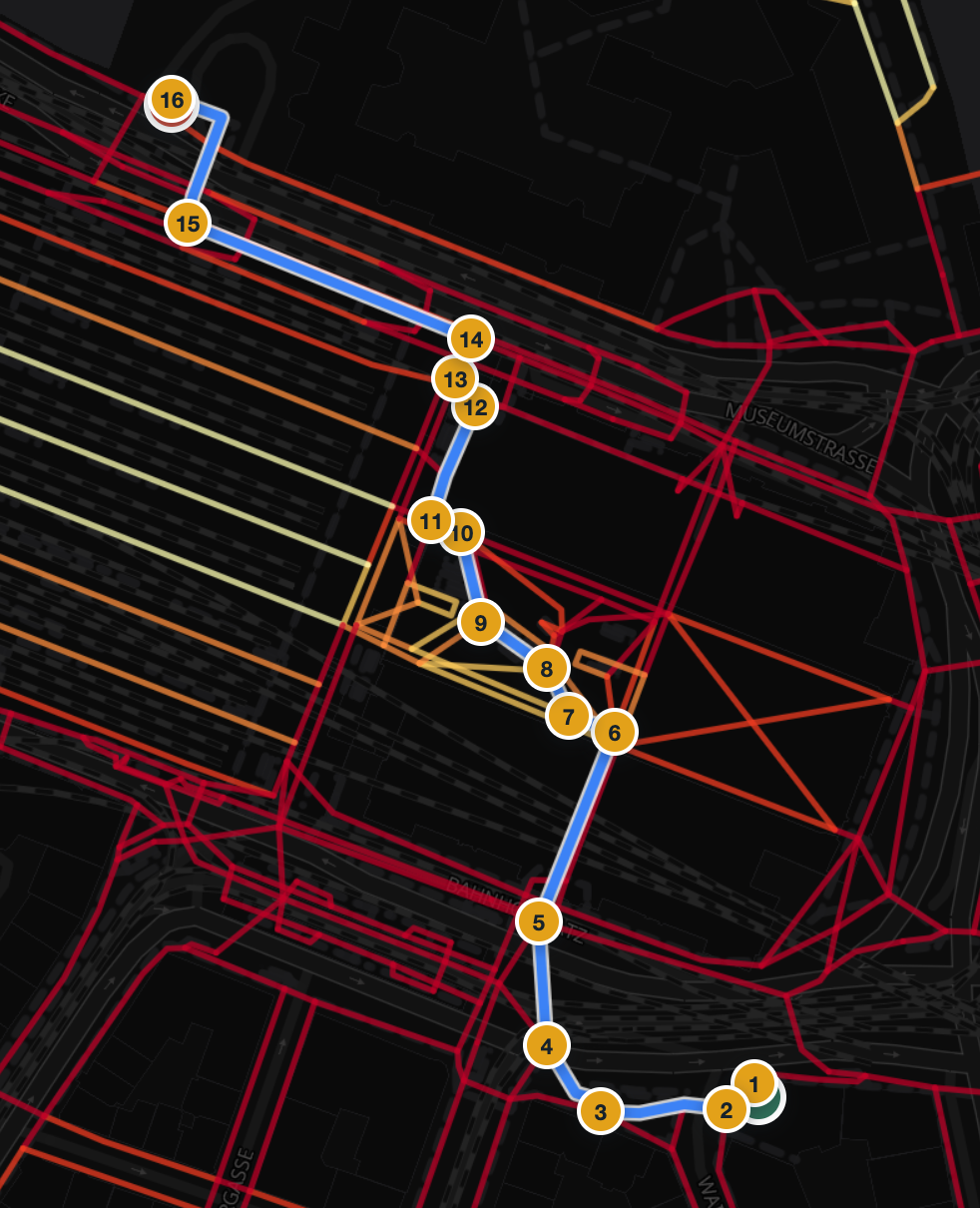
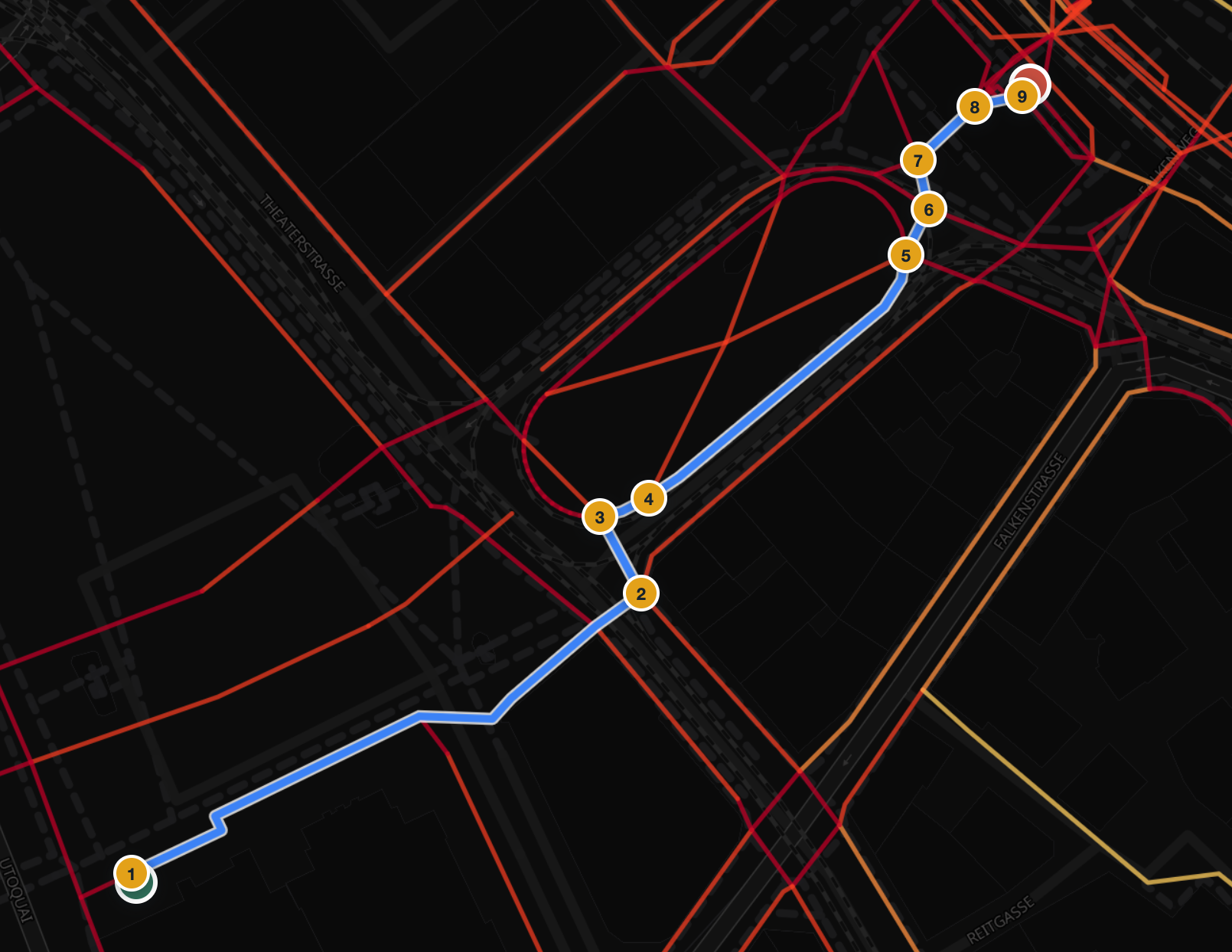
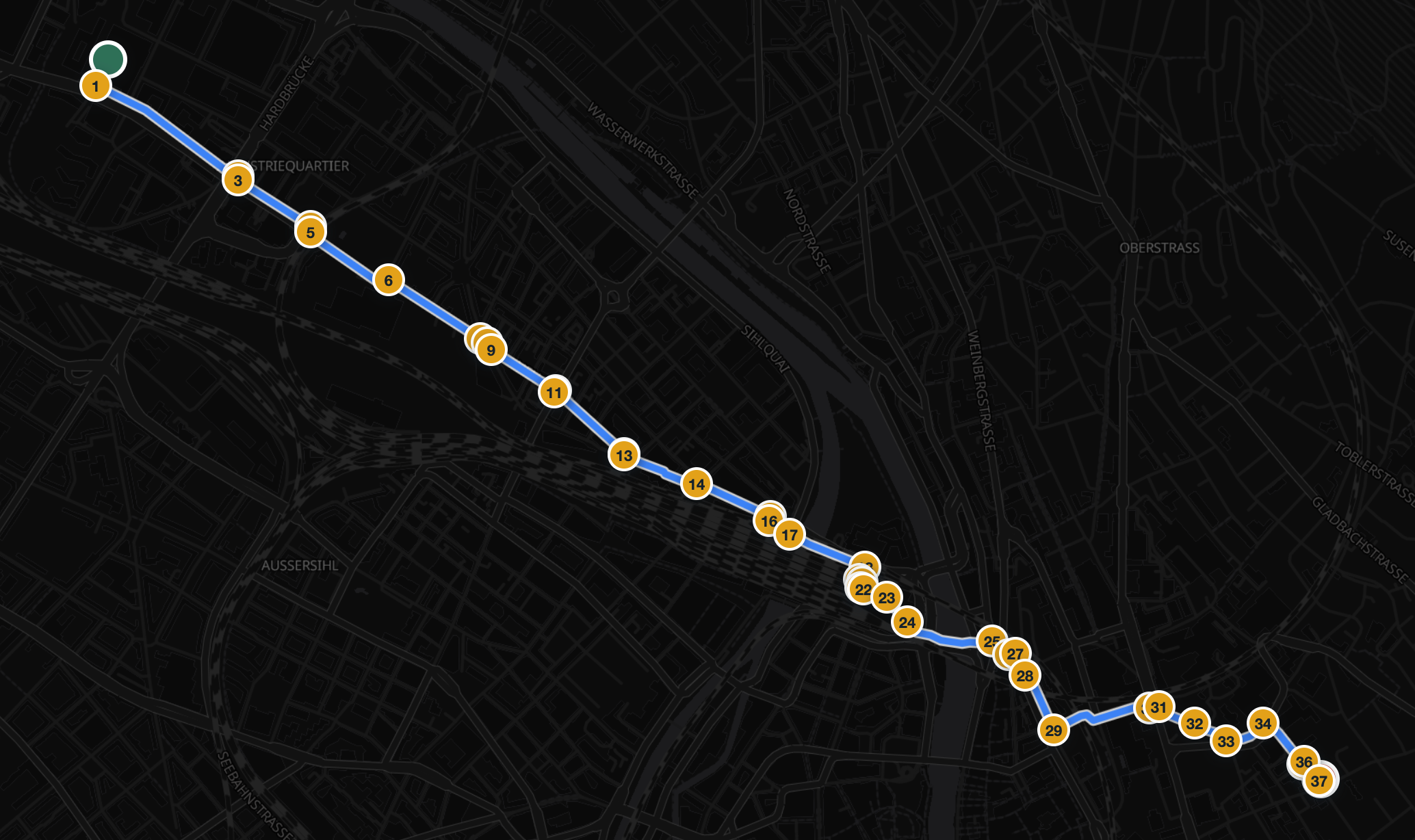
Six real walking routes in Zürich, captured straight from this routing service on the production graph. For every one of the 116 instructions we computed the turn angle, the distance to its neighbours, and the junction structure of the underlying network at that exact point. Every bad instruction got exactly one root-cause tag.
| Route | Distance | Instructions | Per km | Character |
|---|---|---|---|---|
| 1 | 726 m | 12 | 16.5 | Short hop near the station |
| 2 | 4.5 km | 26 | 5.8 | Long cross-town walk |
| 3 | 1.4 km | 16 | 11.6 | Ordinary route, meant as a control |
| 4 | 3.8 km | 37 | 9.7 | Mostly straight, yet 37 instructions |
| 5 | 282 m | 9 | 31.9 | Crossing a square |
| 6 | 420 m | 16 | 38.1 | Through the Hauptbahnhof |
For comparison: a comfortable pedestrian instruction density is roughly 2–4 per km on city routes. Route 6 fires one instruction every 26 metres.
The turn is real to the engine but not to a person: a few degrees of bend announced as a maneuver. Fixable by tuning turn-classification parameters. We found almost none of these.
An instruction fires at a junction where there is no real choice: the alternative is a driveway, a dead end, or an obviously wrong branch. Fixable in anchoring heuristics or by post-processing.
The network itself is so finely chopped that it creates decision points that do not exist on the ground. No instruction generator can fix this; it lives upstream in the graph data. This is our dominant defect.
84 of 116 instructions are defective. 65 are topology, only 4 are threshold (the yellow sliver), 15 await human review. The spike began with the assumption that driving-tuned turn thresholds were the problem. The data says otherwise: the chattiness is in the graph, not the thresholds.
Our foot network is not OSM: it is Stadt Zürich’s Fuss- und Velowegnetz, and the maneuver points snap to its nodes exactly. That network models every crossing island, parallel sidewalk, and station passage as separate segments, so the router sees turns where a person sees a straight walk.
We compared the guidance approaches of GraphHopper, OSRM, Valhalla, and MOTIS expecting a threshold-tuning answer. The defect distribution short-circuits that: tuning turn classification in any engine fixes at most a handful of our defects. The proposed direction is a two-front fix.
| Graph simplification (data pipeline) | Collapse crossing islands, parallel sidewalk stitches, and station-interior micro-segments before the PBF export, so spurious decision points never reach the router. |
|---|---|
| Thin guidance layer (this service) |
Post-process the instruction list: merge micro-maneuver clusters, suppress
announcements at junctions with no meaningful divergence. Valhalla’s
odin and MOTIS’s level-aware
get_step_instructions are the reference implementations worth borrowing
from.
|
| Not the fix | Swapping routing engines, or tuning “slight turn” thresholds in isolation. |
Status: 15 unclear instructions
await human review, then the tripwire decision formally reshapes the rest of the spike. Full data:
reference/guidance-comparison/results/baseline-defects.csv and
results/breakdown.md.